Abstract:
Many algorithms and data structures employing hashing have been
analyzed under the uniform hashing assumption, i.e., the assumption
that hash functions behave like truly random functions. In this paper it is
shown how to implement hash functions that can be evaluated on a RAM in
constant time, and behave like truly random functions on any set of 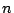 inputs, with high probability. The space needed to represent a function is
inputs, with high probability. The space needed to represent a function is
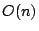 words, which is the best possible (and a polynomial improvement
compared to previous fast hash functions). As a consequence, a broad class of
hashing schemes can be implemented to meet, with high probability, the
performance guarantees of their uniform hashing analysis
words, which is the best possible (and a polynomial improvement
compared to previous fast hash functions). As a consequence, a broad class of
hashing schemes can be implemented to meet, with high probability, the
performance guarantees of their uniform hashing analysis
Available as PostScript, PDF, DVI.